
Vermont Business Magazine In a new study, SmartAsset analyzed data across four metrics to find the states that are most dependent on the federal government, and Vermont ranks in the number five spot. Vermont ranks high in terms of federal funding compared to income taxes paid. For every dollar Vermont sends to the federal government the state gets back $1.14. In that metric, the Green Mountain State ranks sixth. Federal government employees are also big producers in the state’s economy. According to SmartAsset data, the average federal government employee makes 1.89 times what the average worker earns. Vermont ranks eighth in that metric. Vermont's lowest ranking is in percentage of federal workers in the labor force (tied for 33rd). Vermont ranked 18th in percentage of federal share of state revenue.
In order to rank the states most dependent on the federal government, SmartAsset looked at four factors: percent of state government revenue which comes from the federal government; the percent of workers employed by the federal government; the quality of federal jobs; and the ratio of income taxes paid compared to money received from the federal government.
Key Findings
- Southern states are more reliant – According to SmartAsset data, Southern states are more reliant on the federal government than Northern states. SmartAsset top five for example has three Southern states and only one Northern state. The five states least dependent on the federal government include two New England states and no Southern states.
- Federal jobs pay well – In general, federal jobs tend to pay well. The average federal worker earns 1.9 times what the average worker earns across SmartAsset top 10 states. These jobs tend to be relatively rare, though. Only in Maryland does the percent of the workforce employed by the federal government exceed 10%.
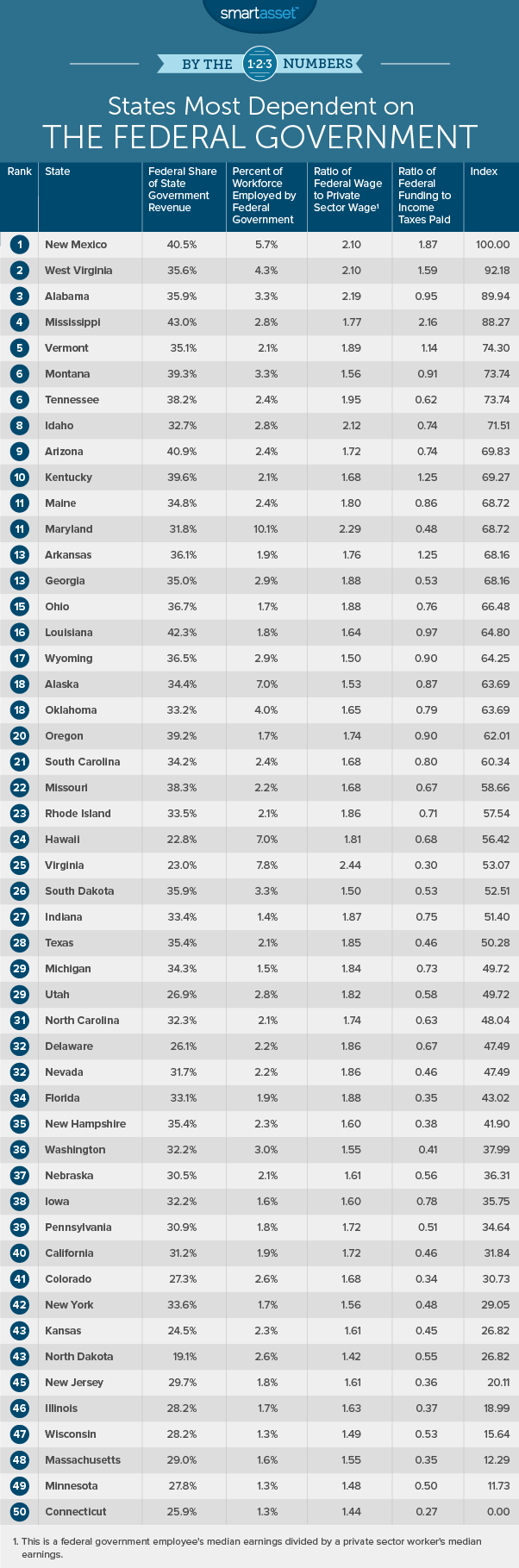
1. New Mexico
Just under 6% of the New Mexico workforce works for the federal government. A large number of these workers are in the military. The National Park Service, United States Forest Service and the United States Bureau of Land Management are also prominent employers.
Compared to the average job, working for the federal government is a good gig. The average federal worker in New Mexico earns over twice as much as the average private sector worker. This state also has the second-highest ratio of federal funding to income taxes paid in the SmartAsset study.
2. West Virginia
Over 35.5% of West Virginia’s government revenue comes from money from the federal government. That’s the 15th-highest number in SmartAsset study. Not only does the federal government provide a large chunk of the state’s budget, a large portion of the West Virginian workforce works for the federal government. The state ranks sixth for share of workers employed by the federal government.
The jobs the federal government provides tend to be some of the best, as well. The average federal government employee in West Virginia makes 2.1 times what the average private sector worker earns.
3. Alabama
About 35.9% of the Alabama state government revenue is provided by the federal government. Alabama also scored high on this study because of the workforce’s dependence on the federal government. Around 3.3% of all workers work for the federal government.
These workers also tend to be some of the best paid. The typical federal government employee makes almost 2.2 times as much as the median private sector worker in Alabama.
4. Mississippi
No state government is more reliant on federal funding than Mississippi. Almost 43% of the state government revenue comes from the federal government. Mississippi residents also do not pay much in taxes relative to the support they get from the federal government. For every dollar Mississippi sends in income tax, they get back $2. In both of these metrics Mississippi ranks first.
5. Vermont
Vermont ranks high in terms of federal funding compared to income taxes paid. For every dollar Vermont sends to the federal government the state gets back $1.14. In that metric, the Green Mountain State ranks sixth.
Federal government employees are also big producers in the state’s economy. According to SmartAsset data, the average federal government employee makes 1.89 times what the average worker earns. Vermont ranks eighth in that metric.
6. (tie) Montana
Montana is home to many of America’s favorite national parks. These parks are primarily managed by the federal government meaning large chunks of the Montana workforce are employed by the federal government. In total 3.3% of all workers are employed by the federal government, the eighth-most in SmartAsset study.
The state also has top 10 scores in percent of state revenue provided by the federal government and federal funding compare to income taxes paid.
6. (tie) Tennessee
Just over 38% of the revenue the state government of Tennessee takes in comes from the federal government. In that metric, Tennessee ranks ninth. Tennessee also scores highly because the federal government provides high-paying jobs. The average worker for the federal government earns 1.95 times what the average person in the private sector workforce earns.
However Tennessee only ranks 27th for income taxes paid relative to federal funding to the state government. That’s also the lowest rank in the top 10.
8. Idaho
Idaho ranks in the top half for three out of SmartAsset four metrics. In particular, Idaho ranks high because of the pay federal government workers earn, compared to the average worker. The average federal government employee here earns 2.12 times the average private sector worker earns.
In total there are about 21,300 federal government employees in Idaho, or 2.8% of the overall workforce.
9. Arizona
Just under 41% of the Arizona state revenue comes from the federal government. In total the federal government sends Arizona over $12.7 billion. There are also 71,000 federal employees out of a total workforce of 3.03 million. That means about 2.5 out of every 100 workers is employed by the federal government.
10. Kentucky
Just under 40% of the Kentucky state revenue comes from the federal government, a top 5 rate. Residents here also get quite a bit of bang for their income tax buck. According to SmartAsset data, Kentucky gets about $1.25 for every dollar in income tax it sends to the federal government.
One area this state is not dependent on the federal government is in employment. This state ranks below average in both of SmartAsset federal government employment metrics.
Data and Methodology
In order to find the states most dependent on the federal government, SmartAsset looked at data for all 50 states. Specifically, SmartAsset looked at the following four factors:
- Federal share of state government revenue. This is the percent of the state government’s revenue which comes from the federal government. Data comes from the U.S. Census Bureau’s 2015 Annual Survey of State and Local Finances.
- Ratio of federal funding to income taxes paid. This is the revenue the federal government gives to the state government divided by the amount of income tax paid by the state. Data comes from the U.S. Census Bureau’s 2016 1-Year American Community Survey and the IRS Individual Income and Tax Data for 2015.
- Percent of workers employed by the federal government. This is the percent of the overall workforce employed by the federal government. Data comes from the U.S. Census Bureau’s 2016 1-year American Community Survey.
- Ratio of federal wage to private sector wage. This is a federal government employee’s median earnings divided by a private sector worker’s median earnings. Data comes from the U.S. Bureau’s 2016 1-year American Community Survey.
SmartAsset ranked each state in each metric. Then it found each state’s average ranking. SmartAsset then used this average ranking to create its final score. The state with the best average ranking received a 100. The state with the worst average ranking received a 0.
Source: SmartAsset. 1.18.2018. Details on the study, including full methodology and rankings, can be found here: https://smartasset.com/taxes/states-most-dependent-on-the-federal-government.